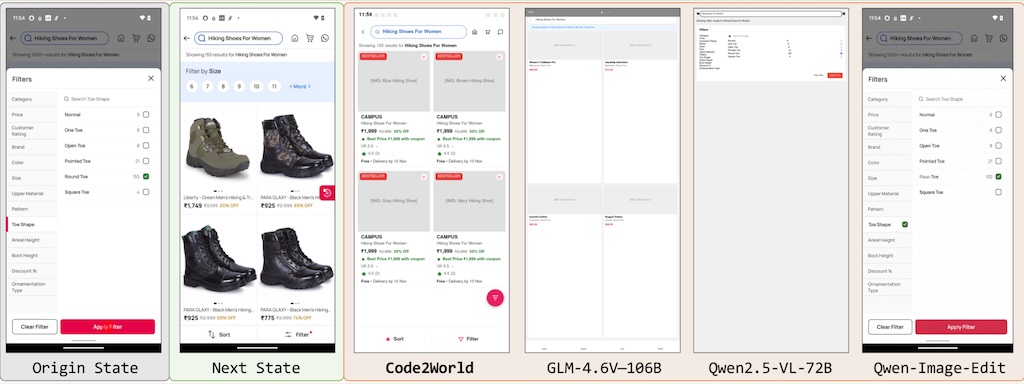
Code2World 本身不是一個「GUI 設計工具」,但它可以用在「優化 GUI 設計」的流程裡,特別是幫你 驗證設計是否好操作、是否容易出錯、是否符合使用者行為預期。Code2World 以靈活的方式顯著提升了下游導航的成功率,在 AndroidWorld 導航方面,其性能比 Gemini-2.5-Flash 提升了 9.5%。
它透過產生可渲染的程式碼來模擬下一個視覺狀態。實驗表明,Code2World-8B 在下一界面 UI 預測方面表現卓越,足以媲美 GPT-5 和 Gemini-3-Pro-Image 等競爭對手。(Huggingface 模型及數據集出現 404)(圖為預測介面的結果)