I Found HIDDEN Nano Banana Pro Prompts No One Shares! (Part 2) | Nano Banana Pro Tutorial 2026


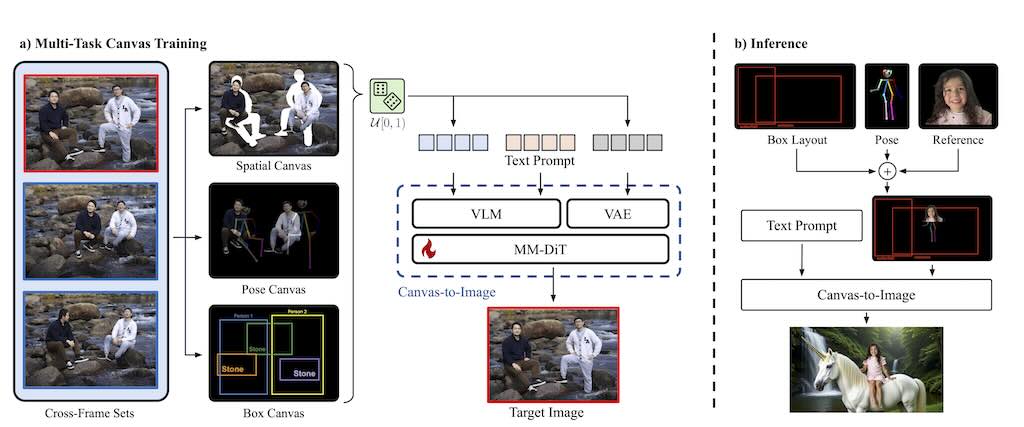
Canvas-to-Image 是個統一的框架,它將構圖控制整合到一個單一的介面中。能夠將主體、邊界框和姿態骨架在內的各種控制訊號編碼到一個單一的合成影像中,模型可以直接解讀該影像以進行整合的視覺空間推理。(未見源碼)

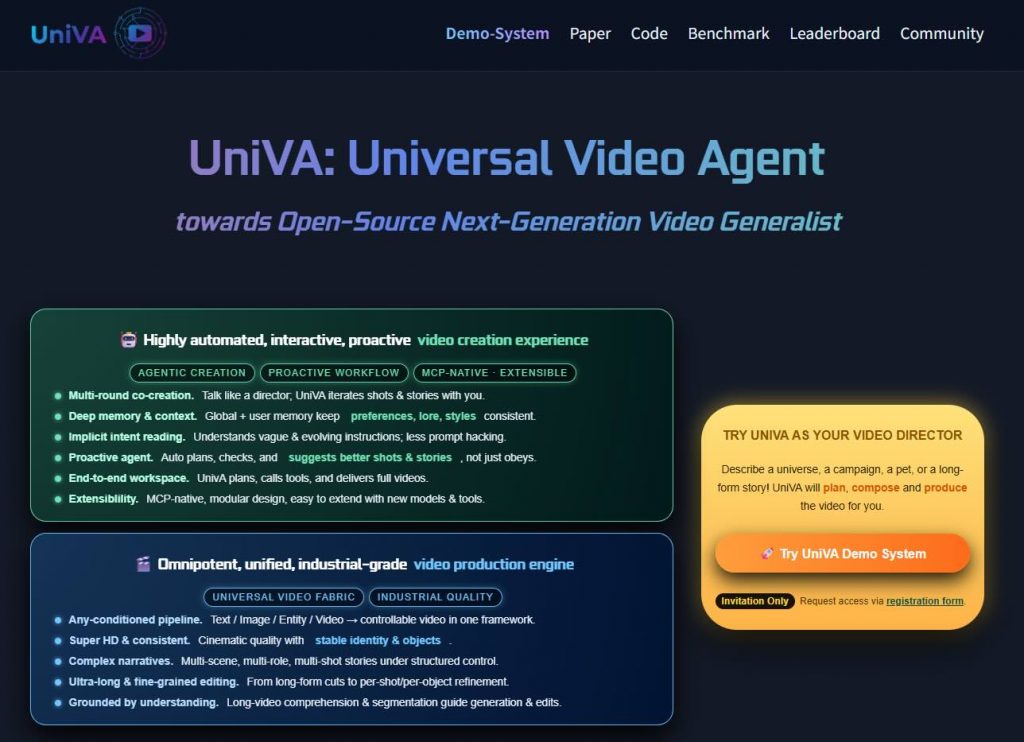
一套開源、多代理的「全能型影片處理框架」UniVA,目的是將影片理解、分割、剪輯與生成等功能統合成自動化且可擴展的工作流程。

最近 AI 生成技術越來越流行應用 image to video,其中最常見的是駛用(first frame)和(last frame)作為提示(prompt)來引導 AI 模型產生更平滑的影片延續效果。令到生成的影片更加有連貫性。例如想由一個影片平滑過渡到另一個影片。ElFrame 正是專為這種工作流設計的簡單輔助工具,它專注影片快速提取最後一幀,用家能夠輕鬆攞到這些關鍵圖像作為後續 AI 生成的輸入。
ElFrame 是一個免費的(Video Frame Extractor),可以快速提取影片的任何一幀。這些提取出的圖像可以直接用於像 Wan 2.1 的 First-Last-Frame to Video 或者其他類似的 AI 工具(例如 Veo3、Luma Dream Machine、Runway ML),作為生成影片的邊界提示,減少生成過程的抖動和不連貫問題。順帶一提,呢個免費服務係由 OpenSpec 協助一邊睇戲一邊自動生成!

開源 Cosmos DiffusionRenderer 是一個視訊擴散框架,用於高品質影像和視訊的去光和重光。它是原始
DiffusionRenderer 的重大更新,在 NVIDIA 改進的資料管理流程的支持下,實現了顯著更高品質的結果。
最低要求 Python 3.10 NVIDIA GPU 至少配備 16GB VRAM,建議配備 >=48GB VRAM NVIDIA 驅動程式和 CUDA 12.0 或更高版本 至少 70GB 可用磁碟空間

教學:

