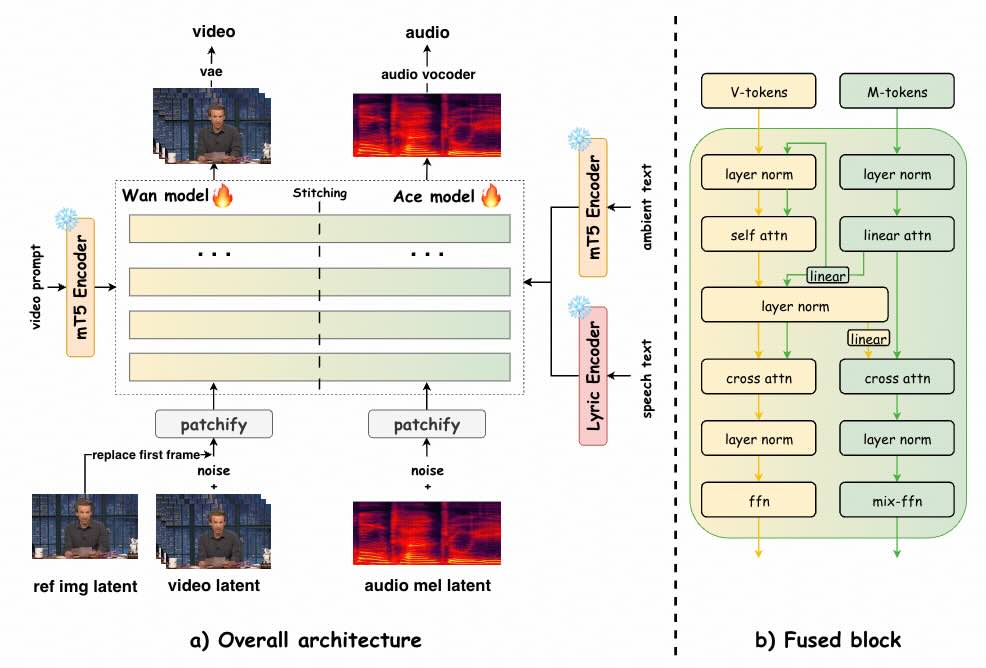
「Qwen3-VL-Embedding-2B」是 Qwen 家族中最新的多模態信息檢索和交叉模態理解模型。可在同一向量空間做相似度計算,方便做「跨模態檢索」與「圖文混合檢索」。
Embedding 維度可控:預設最高 2048 維,但支援使用者自訂輸出維度 64–2048,可依儲存成本與下游模型需求調整(例如 256/512 維用於向量 DB)。
模型規模與 context length:2B 參數,context 長度 32k,適合放在邊緣或低資源伺服器上,同時能處理長文檔、多 frame 影片描述等輸入。
| 模型 | Gemini Multimodal Embeddings | Qwen3-VL-Embedding (2B/8B) |
|---|---|---|
| 模態支援 | 文字、圖片、video(含 audio 軌道,1 FPS + 音頻特徵) | 文字、圖片、截圖、video(多 frame),混合任意組合 |
| 語言 | 多語(英文主導) | 30+ 語言,強中文/多語對齊 |
| 維度 | 固定 1408 | 可自訂 64–4096(預設 2048) |
| Context | Video 上限 1-3 小時 | 32K tokens(長影片多 frame) |
| 開源 | 否(API) | 是(HF/GitHub,Apache 2.0) |
| 成本 | $0.0001/1000 chars(text),更高 video/image | 免費本地,GPU 硬體成本 |
| 整合 | Vertex AI / Gemini API,易 scale | Transformers/vLLM,量化友好 |
- 1. 圖像和文本檢索系統:可以用於基於文本描述搜索相關圖像,或者基於圖像內容搜索相關文本描述。
- 2. 視頻推薦平台:將視頻和文本描述映射到共享表示空間,以提高視頻推薦的準確性。
- 3. 多模態內容管理:對於包含圖像、文本和視頻的大型數據集,可以進行有效的內容聚類和組織。
- 4. 社交媒體分析:分析和理解跨文本和圖像的用戶生成內容。
- 5. 教育和培訓:藉助於視覺問答和多模態學習材料,提供個性化的學習體驗。