Cinematic AI Tutorial Showdown: Kling O1 vs. Nano Banana (Google Flow)


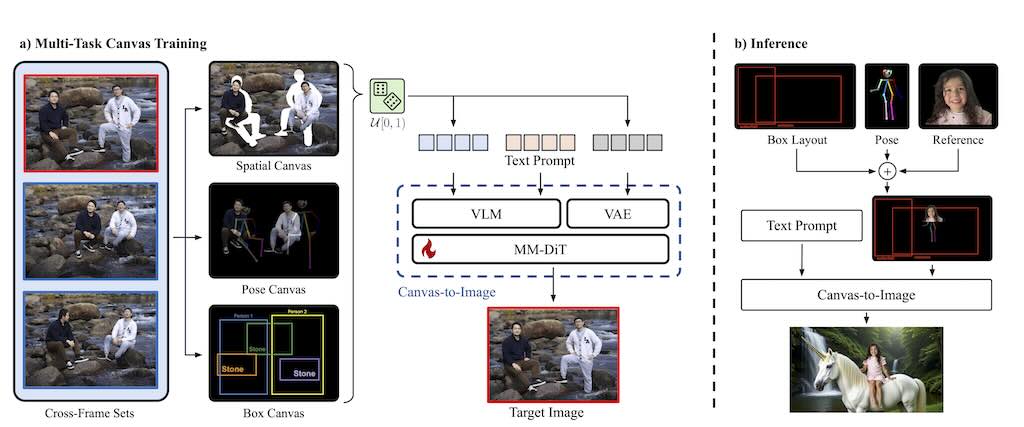
Canvas-to-Image 是個統一的框架,它將構圖控制整合到一個單一的介面中。能夠將主體、邊界框和姿態骨架在內的各種控制訊號編碼到一個單一的合成影像中,模型可以直接解讀該影像以進行整合的視覺空間推理。(未見源碼)
Z Image Turbo 支持 ComfyUI,它採用 qwen_3_4b.safetensors 的 Text encoder 及 Flux 1 VAE 。

Z-Image 是一款功能強大且高效的影像生成模型,擁有60 億個參數。目前共有三個版本:
🚀 Z-Image-Turbo – Z-Image 的精簡版,僅需8 次函數評估 (NFE),即可達到甚至超越領先競爭對手的性能。它在企業級 H800 GPU 上可實現⚡️亞秒級推理延遲⚡️,並能輕鬆適配16G 顯存的消費級設備。它在照片級圖像生成、雙語文字渲染(中英文)以及強大的指令執行能力方面表現卓越。
🧱 Z-Image-Base – 未經精簡的基礎模型。透過發布此版本,我們旨在充分釋放社群驅動的微調和自訂開發的潛力。
✍️ Z-Image-Edit – Z-Image 的一個衍生版本,專為影像編輯任務而最佳化。它支援創意圖像到圖像的生成,並具備強大的指令跟隨功能,允許根據自然語言提示進行精確編輯。



科學研究不斷表明,真正的學習需要積極參與。這正是 Gemini 幫助您學習的根本所在。除了簡單的文字和靜態圖像,我們現在還在Gemini 應用中推出互動式圖像——這項新功能旨在幫助您以視覺化的方式探索複雜的學術概念。
想像你在研究消化系統或細胞結構。現在,你不再只能看到標籤,而是可以直接點擊圖表中的特定部分,解鎖一個互動式面板。此面板提供即時定義、詳細解釋以及可供深入研究的內容。
透過與圖像互動,Gemini 將學習方式從被動觀看轉變為主動探索。現在,透過某些影像,您可以獲得更多相關主題資訊並提出後續問題。這標誌著學習方式朝著更直覺、更動態、更易於理解的方向邁出了重要一步。
影片教你怎樣用「ComfyUI + OVI 11B」在低 VRAM 顯示卡上做 10 秒有畫又有聲嘅影片生成功能,重點係一步步教你放啱模型檔、設定 workflow,同埋用 LoRA 喺低 steps 都保持畫質。

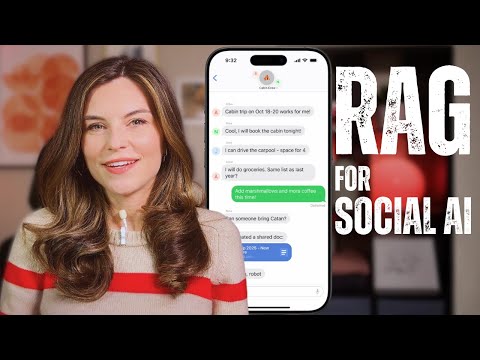
在 RAG(檢索增強生成,Retrieval-Augmented Generation)流程中融合 HyDE 技術,特別是在社交群組 AI 助理的應用場景。影片詳細說明了 RAG 的基本原理、技術演進、現實挑戰,以及 HyDE 方法如何解決多輪群聊語意檢索問題、具體提升個人化推薦的效果。
這案例對 RAG 技術實戰落地非常有啟發,尤其在社群、記憶建構、個人化需求場景的處理方式。若你有自己的群聊 AI 專案,這種查詢增強流程、高維語意檢索建議、如何平衡效率與準確,是值得深入借鑑的。