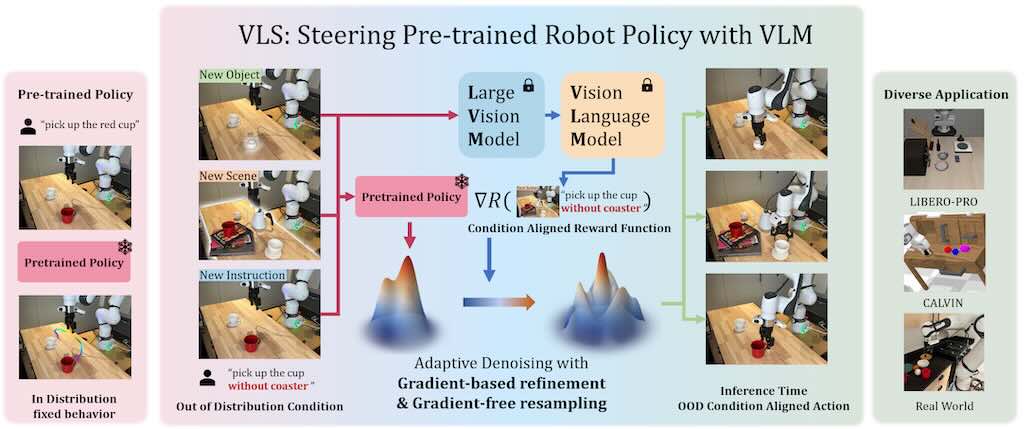
VLS(Vision-Language Steering)的具體作用是透過視覺語言模型(VLM)即時導向預訓練機器人策略,解決測試時的分布偏移,讓機器人在新環境中保持高成功率,而無需重新訓練。
VLS 針對預訓練擴散策略在空間變化(如新位置)或任務變化(如新物件)下的失效,提供無梯度、無訓練的適應機制,利用 VLM 生成可微分獎勵函數,注入去噪過程。
它將任務分解為順序階段(如「抓取」→「放置」),使用 3D 關鍵點獎勵,避免單一失敗導致整體崩潰。
| 場景 | 無 VLS 成功率 | 有 VLS 成功率 | 提升幅度 |
|---|---|---|---|
| 任務擾動 | 23% | 38% | +15% |
| 位置擾動 | 24% | 35% | +11% |
| 真實廚房任務 | ~50% | 85% | +35% |