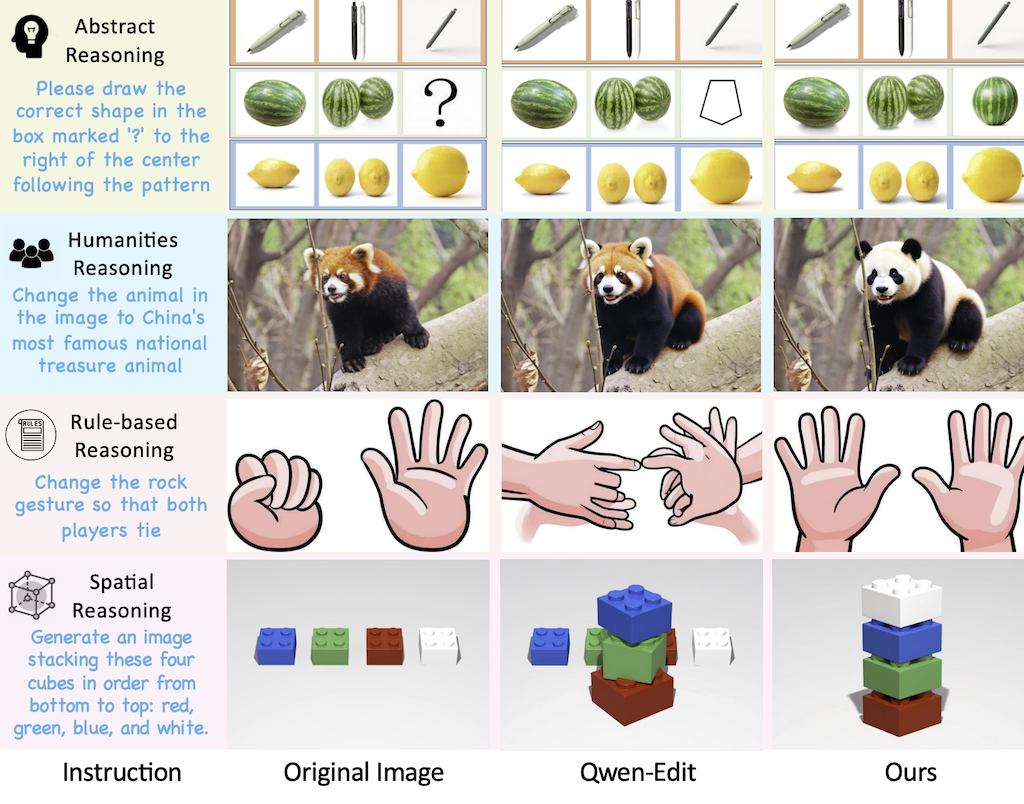
由 ByteDance (字節跳動)提出 ThinkRL‑Edit: Thinking in Reinforcement Learning for Reasoning‑Centric Image Editing「推理導向」圖像編輯,指現有的 RL‑based 編輯方案受限於三個問題:探索空間只在去噪隨機性、獎勵函數的加權不夠公平、以及 VLM 判斷獎勵可能不穩定。作者提出的 ThinkRL‑Edit 框架將視覺推理與影像合成分開,並利用 Chain‑of‑Thought 產生多層次的推理樣本,包含策劃與自省兩個階段,讓模型在實際產生圖像前先評估多種語意假設的可行性。這樣的設計讓探索不再受到去噪過程的束縛,並透過無偏的獎勵策略提升圖像編輯的精確度與一致性。