CogVideo 文字 > 影片產生 GitHub – THUDM/CogVideo: Text-to-video generation: CogVideoX (2024) and CogVideo (ICLR 2023)Text-to-video generation: CogVideoX (2024) and CogVideo (ICLR 2023) – THUDM/CogVideo
GraphRAG – Llama 3.1 和 Neo4j 本影片介紹如何使用開源模型執行 GraphRAG – Llama 3.1 和 Neo4j 作為圖形資料庫 Local GraphRAG with LLaMa 3.1 - LangChain, Ollama & Neo4jWatch this video on YouTube
SmolLM – 全開源模型 – 速度極快且功能強大 透過開源和開放科學來推進人工智慧並使之民主化模型在各種基準、測試常識推理和世界知識的規模類別中均優於其他模型 數據集包括 3000 萬份教科書、部落格文章及故事組成。
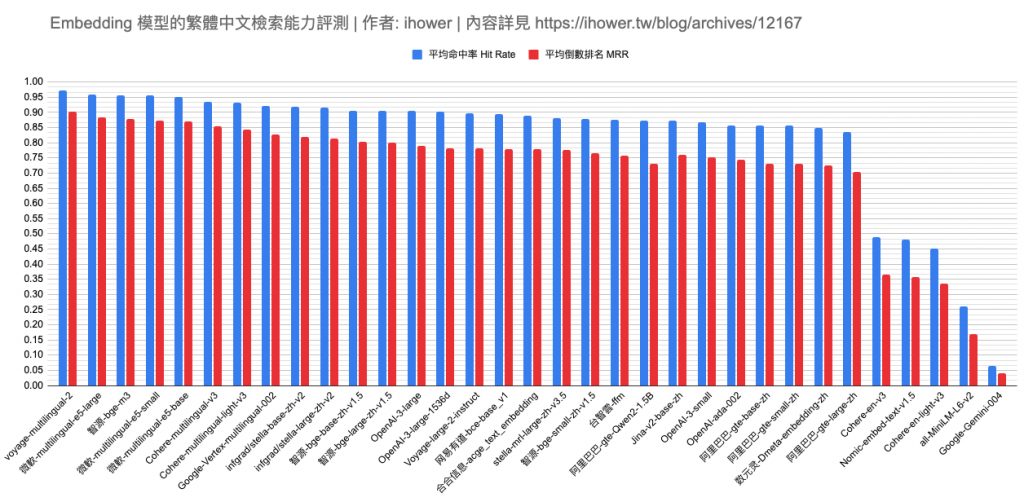
繁體中文評測各家 Embedding 模型的檢索能力 使用繁體中文評測各家 Embedding 模型的檢索能力歡迎訂閱 愛好 Generative AI Engineer 電子報 aihao.eo.page/a…
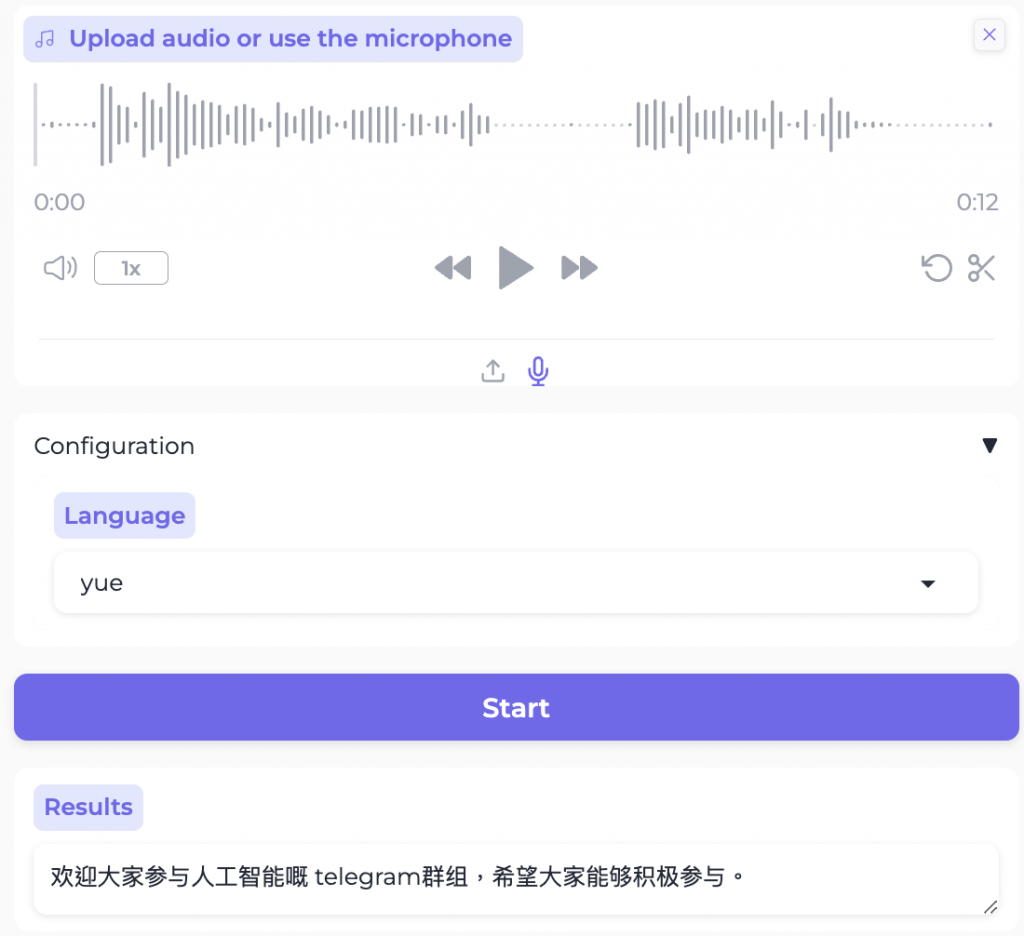
SenseVoice 具有音頻理解能力的音頻基礎模型 語音識別(ASR)、語種識別(LID)、語音情感識別(SER)和聲學事件分類(AEC)或聲學事件檢測(AED)在多個任務測試集上的benchmark,以及體驗模型所需的環境安裝的與推理方式。 Mac M1 上實測,廣東話夾英文一齊都好準,不過出嘅係簡體中文!
Meta Chameleon – 多模態開源模型 (英)Meta 的 FAIR 團隊公開 Chameleon 模型於研究用Chameleon 的成功在於其完全基於 Token 的架構。模型將會同時學習圖像和文字,進行聯合推理,這對於分開編碼器的模型來說,令推理更接近 Reasoning 的要求,儘管存在一些限制。
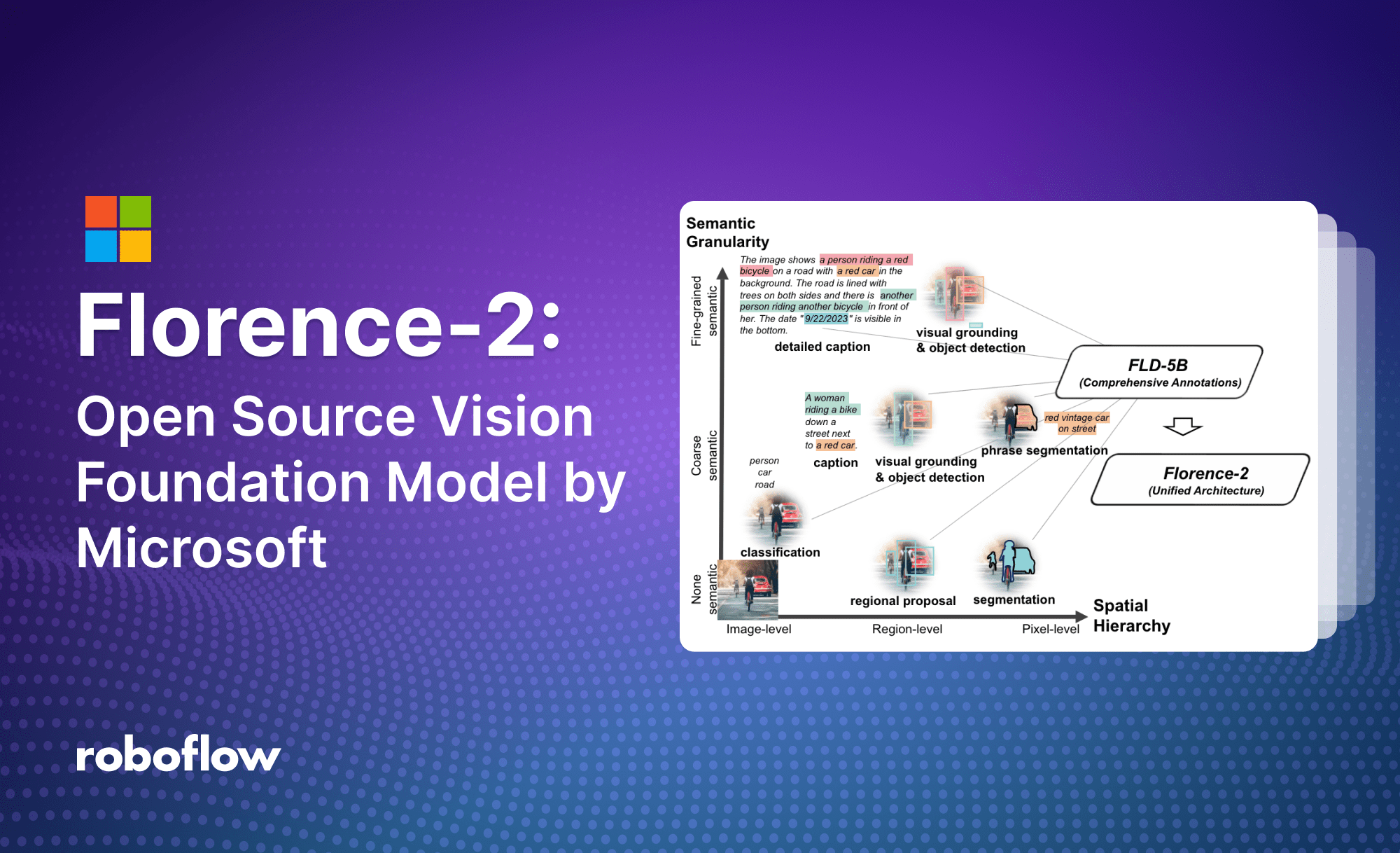
Florence-2 (Microsoft)開源模型 – 影像識別 (英)輕量級視覺語言模型模型在字幕、物件偵測、接地和分割等任務中展示了強大的零樣本和微調功能。 繼 Meta 推出多模態 open source 模型,Microsoft 也不甘後人,推出影像識別 Open source Florence-2 模型 儘管尺寸很小,但它所取得的結果與大許多倍的模型(如 Kosmos-2)相當。該模型的優勢不在於複雜的架構,而在於大規模的 FLD-5B 資料集,其中包含 1.26 億張影像和 54 億個綜合視覺註釋。
Llama中文社區,所有代碼更新適配Llama3 GitHub – LlamaFamily/Llama-Chinese: Llama中文社區Llama中文社區,Llama3在線體驗和微調模型已開放,實時匯總最新Llama3學習資料,已將所有代碼更新適配Llama3,構建最好的中文Llama大模型,完全開源可商用
parler-tts: 高品質 TTS 模型的推理和訓練庫 Parler-TTS 的文本轉語音庫。Parler-TTS 是開源的,允許用戶生成各種風格的語音。文章詳細說明安裝及使用方法。 Parler-TTS 十分輕量,可以通過一行代碼安裝。此外,模型仍處於開發中,目標是將來使用更多的數據進行訓練。 (英) parler-tts: Inference and training library for high-quality TTS models.Inference and training library for high-quality TTS models. – huggingface/parler-tts