MTVCrafter 是專門用來製作高品質的數字人動畫。現有方法依賴二維渲染的姿態影像進行運動引導,這限制了其泛化能力並丟棄了重要的三維資訊。MTVCrafter 有兩個厲害的設計:第一個是 4DMoT(4D 運動標記器),能夠將三維動作轉成 4D 運動標記,比二維圖片更精準地捕捉時間和空間的細節!第二個是 MV-DiT(運動感知影片 DiT),用了一個特別的 4D 位置編碼技術,讓動畫在複雜的三維世界裡也能流暢又生動。實驗結果的 FID-VID 分數達到 6.98,比第二名強了 65%,不管是單人、多人、全身或半身的角色,還是各種風格和場景,它都能輕鬆搞定!
Gemma 3n
Gemma 3n 是一款開源生成式 AI 模型,針對手機、筆記型電腦和平板電腦等日常設備進行了最佳化。包括逐層嵌入 (PLE) 參數快取和 MatFormer 模型架構,可靈活降低運算和記憶體需求。模型同時具備音訊輸入處理、文字和視覺資料處理等功能。
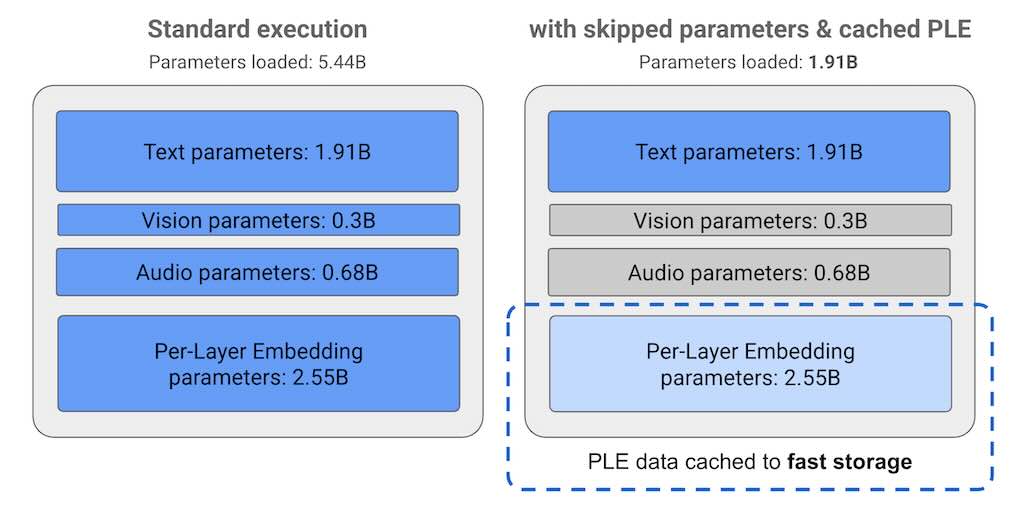
Gemma 3n 模型的參數在 E2B 模型的標準執行過程中,執行模型時會載入超過 50 億個參數。然而,使用參數跳過和 PLE 快取技術,該模型可以在有效記憶體負載略低於 20 億(19.1 億)個參數的情況下運行。Huggingface 下載
Announcing Gemma 3n Preview: Powerful, Efficient, Mobile-First AI

Gemini CLI:您的開源 AI 代理
Google 推出了 Gemini CLI,一個免費的開源項目。它允許開發者透過自然語言指令在 Terminal 使用 Google 的 Gemini 2.5 Pro 模型。它可以編寫程式碼,亦能夠處理內容的生成、或者解決問題、甚至深入研究和任務管理等的多種任務。這個工具的設計目標是提升開發者在終端機中的工作效率,令 AI 成為日常工作流程的一部分。

AlphaEvolve 無限智慧
– Google Deepmind A.I.
AlphaEvolve 無限智慧 - Google Deepmind A.I.

從零寫AI RAG 個人知識庫
影片中,作者使用了 Google 的 embedding 模型和 ChromaDB 向量資料庫來實現這個架構。
- RAG 架構簡介 解釋了 RAG 的基本原理,即將長文章拆分成小片段,對每個片段進行 embedding,然後儲存到向量資料庫中,並在使用者提問時找出最相關的片段發送給大型語言模型。
- 文章分塊 示範如何將一篇關於「令狐沖轉生為史萊姆」的虛構文章進行分塊處理。他首先使用雙回車符作為切分依據,然後進一步優化,將以警號開頭的標題與後續的正文合併。
- Embedding 與資料庫儲存 介紹如何使用 Google 的 embedding 模型對分塊後的文本進行 embedding,並將這些 embedding 及其原始文本儲存到 ChromaDB 向量資料庫中。作者特別提到 Google embedding 模型的「儲存」和「查詢」兩種模式。
- 查詢功能 說明如何透過查詢 embedding 模型並從 ChromaDB 中檢索出與使用者問題最相關的文本片段。
- 整合大型語言模型 最後,展示如何將查詢到的相關文本片段與使用者問題一起發送給大型語言模型(Gemini Flash 2.5),以生成更準確的回應。
影片強調動手實作的重要性,鼓勵觀眾親自寫一遍程式碼以加深理解。
从零写AI RAG 个人知识库

Circuit Tracing 開源電路追蹤工具
在 Anthropic 最近的研究中,引入了一種追蹤大型語言模型思想的新方法。今天,他們開放該方法的源代碼,以便任何人都可以藉鑑我們的研究成果。
您可以造訪 Neuronpedia 介面 來產生和查看您選擇的提示的歸因圖。對於更複雜的使用和研究,您可以查看 程式碼庫。此版本使研究人員能夠:
- 透過產生自己的歸因圖來追蹤支援模型上的電路;
- 在互動前端中視覺化、註釋和共享圖表;
- 透過修改特徵值並觀察模型輸出如何變化來檢驗假設。
Claude 4 令人驚訝的提示規則
使用 Claude 4 和許多其他進階推理模型(例如 03、Gemini 2.5 Pro 等)需要一種新型的提示詞技巧,這與舊模型的提示方式完全不同,甚至有時是矛盾的。這些技巧很多是從 Anthropic 的一篇部落格文章中擷取,直接來自創造這些模型的研究團隊的建議。
Claude 4's Surprising Prompt Rules Nobody Told You

n8n 與 ComfyUI 自動化生成本地 AI 視頻
教程展示了AI工具鏈整合的未來趨勢,將碎片化任務轉爲端到端自動化系統,適合想提升創作效率的技術型用戶。若需實作細節,可參考影片中的Docker指令與節點配置截圖。
n8n with ComfyUI AI Video Automation Local Setup Walkthrough

中國 AI 產業重大突破的分析與評論
影片討論了中國AI技術在多模態模型和圖像生成方面的重大突破,以及中國在全球AI競賽中逐漸展現出的技術和能源優勢,對未來產業格局產生深遠影響。
中國在電力產能上的快速增長(目前佔全球30%以上,並以每18個月增加一個美國總產能的速度擴張),將成為未來AI競賽的關鍵優勢,因為AI訓練和應用極度依賴能源供應。
TikTok's New AI Just Beat Google and OpenAI in 38 Tests!

100+ 看來與電影一模一樣的 AI 視頻
100+ AI Videos That Look EXACTLY Like Movies
